
4 Strategies to Stop Your AI Agent From Getting Dumb
Key context engineering methods every engineer should know.


Lately, I’ve been diving deeper into the fundamentals of AI agents. One of the most important emerging trends is Context Engineering.
Context engineering is the #1 job for engineers building effective AI agents.
Being skilled at context engineering is more valuable than being fluent in any framework or programming language.
To clarify the difference:
Prompt engineering is about crafting the exact wording of a single prompt to get the best immediate response from an AI model.
Context engineering goes further: it designs the entire environment of inputs the model sees over time. This includes:
Instructions: prompts, memories, few‑shot examples, tool descriptions, etc
Knowledge: facts, memories, etc
Tools: feedback from tool calls
When AI agents start operating, their conversations can span hundreds of turns. This leads to context bloat (an overloaded context that causes context rot).
Context rot means the LLM effectively becomes “dumber” as its context grows too large.
You’ll notice that tools like Claude Code offer features to clear or compact context, which helps make the LLM less dumb.

So, what strategies are used today? According to Lance Martin (software engineer at LangChain), there are four key strategies for context engineering.
#1 Strategy: Write Context
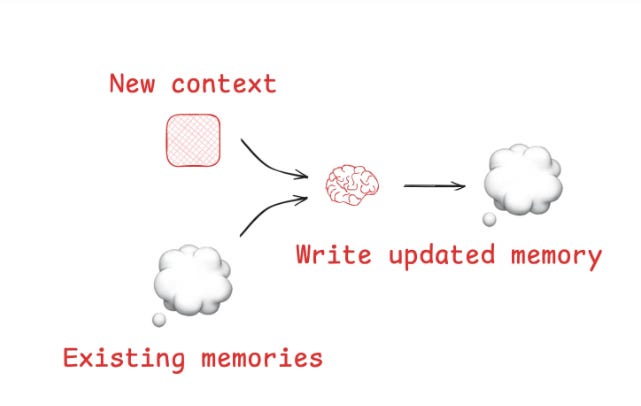
Writing context is about giving agents a memory — saving information outside the token-limited window so they can think and act more like humans who take notes and recall past lessons.
Scratchpads as note-taking tools
Agents can persist key details during a task by writing to a scratchpad (e.g., a file or a runtime field). This ensures important plans or steps aren’t lost when the context window overflows. Anthropic’s multi-agent researcher shows this in practice: a LeadResearcher agent saves its plan to memory before hitting the 200k-token cutoff.
Session-level vs. long-term memory
Scratchpads help within a single task, but agents also need continuity across sessions. Reflexion tackled this by letting agents reflect after each turn and re-use those reflections later.
Building synthetic memories
Generative Agents advanced this by periodically condensing past feedback into new, more structured memories. This gives agents a growing base of knowledge to draw from.
#2 Strategy: Select Context
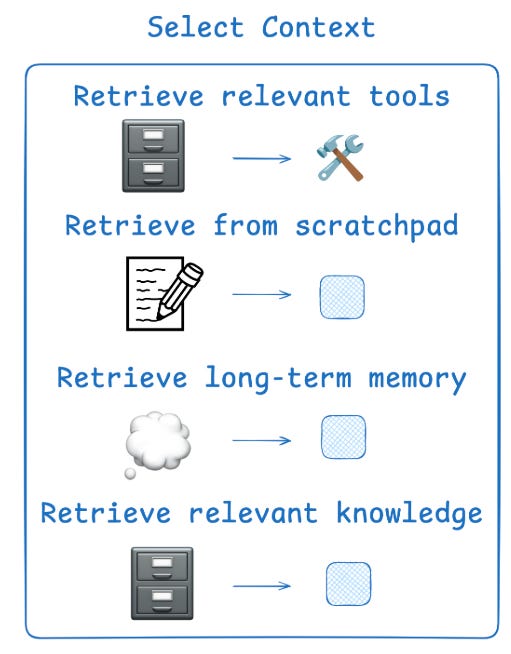
Selecting the right context is about giving the agent just what it needs — nothing more, nothing less. The challenge: too little context makes it clueless, too much context makes it confused.
Scratchpad: Developers decide what parts of the agent’s runtime state (or scratchpad tool) to expose at each step for fine-grained control.
Memories: Agents can pull in episodic (examples), procedural (instructions), or semantic (facts) memories. But Selecting the right ones is tricky. Large memory stores often require embeddings or knowledge graphs.
Tools: Too many overlapping tool descriptions confuse models; RAG-based retrieval helps fetch the right tool for the job, boosting accuracy.
Knowledge: RAG is the keyword here and it is a topic on it’s own.
#3 Strategy: Compress Context
Compressing context is about keeping only what matters and summarizing or trimming interactions so the agent doesn’t drown in tokens.
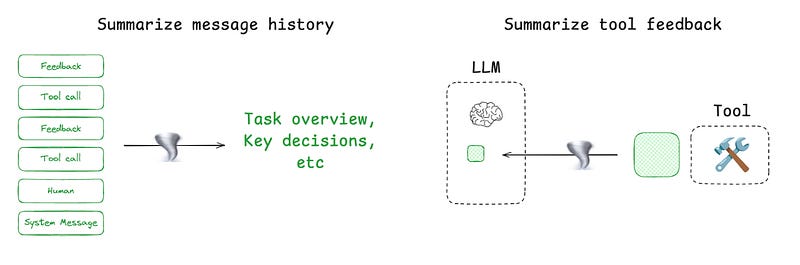
Summarization for long runs: Claude Code shows this with its “auto-compact” feature, which kicks in when the context window hits 95%, summarizing the entire history. Strategies can be recursive (summarize chunks, then summarize the summaries) or hierarchical.
Strategic summarization: Useful at specific points, like condensing results from token-heavy search tools or at agent-to-agent boundaries to cut down hand-off size.
Trimming (pruning): Instead of distilling meaning with an LLM, trimming uses rules or trained filters to drop less important context. Example: cutting older messages from a chat history or using Provence, a trained context pruner for Q&A tasks.
#4 Strategy: Isolating Context
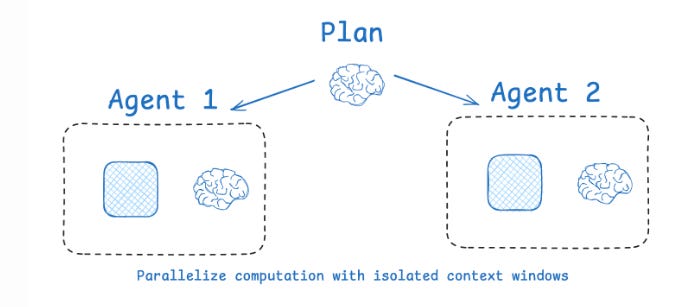
Isolating context is about splitting information so agents can work smarter whether by delegating tasks to multiple agents, sandboxing with code, or structuring state.
Multi-agent setups: OpenAI’s Swarm library uses “separation of concerns,” giving each agent its own tools and context. Anthropic found that sub-agents with isolated contexts often outperform single agents, since each can focus tightly on one task. However, this can cost up to 15× more tokens and requires careful planning to coordinate.
Sandboxed environments: Hugging Face’s CodeAgent isolates context by generating code that makes tool calls in a sandbox. Instead of the LLM holding everything, results like images or audio files can live in the environment’s state as variables, saving tokens and keeping context clean.
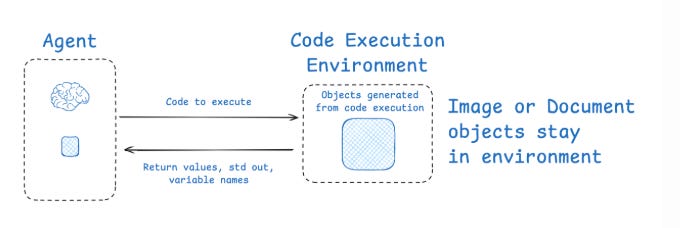
Structured runtime state: Agents can use a schema (like a Pydantic model) to separate what gets exposed to the LLM from what stays hidden. For example, only the “messages” field is visible, while heavy or sensitive data stays in isolated fields for selective use.